Stellt euch vor, ihr lebt mit mehreren Personen in einer Wohnung und jemand von denen hat sich mit SARS-CoV-2 infiziert. Wie schafft ihr es, dass alle anderen uninfiziert bleiben? Vor knapp zwei Jahren habe ich mir die Frage gestellt und mir ein “Konzept” überlegt. Über diesen Zeitraum habe ich immer mal wieder darüber nachgedacht und Änderungen vorgenommen. Nun kam der Zeitpunkt, wo ich mein Konzept mal live testen kann und weitere Änderungen machte. Ich will euch meine Ideen mal unten vorstellen. Solltet ihr Verbesserungen oder Fragen haben, freue ich mich natürlich über Kommentare.
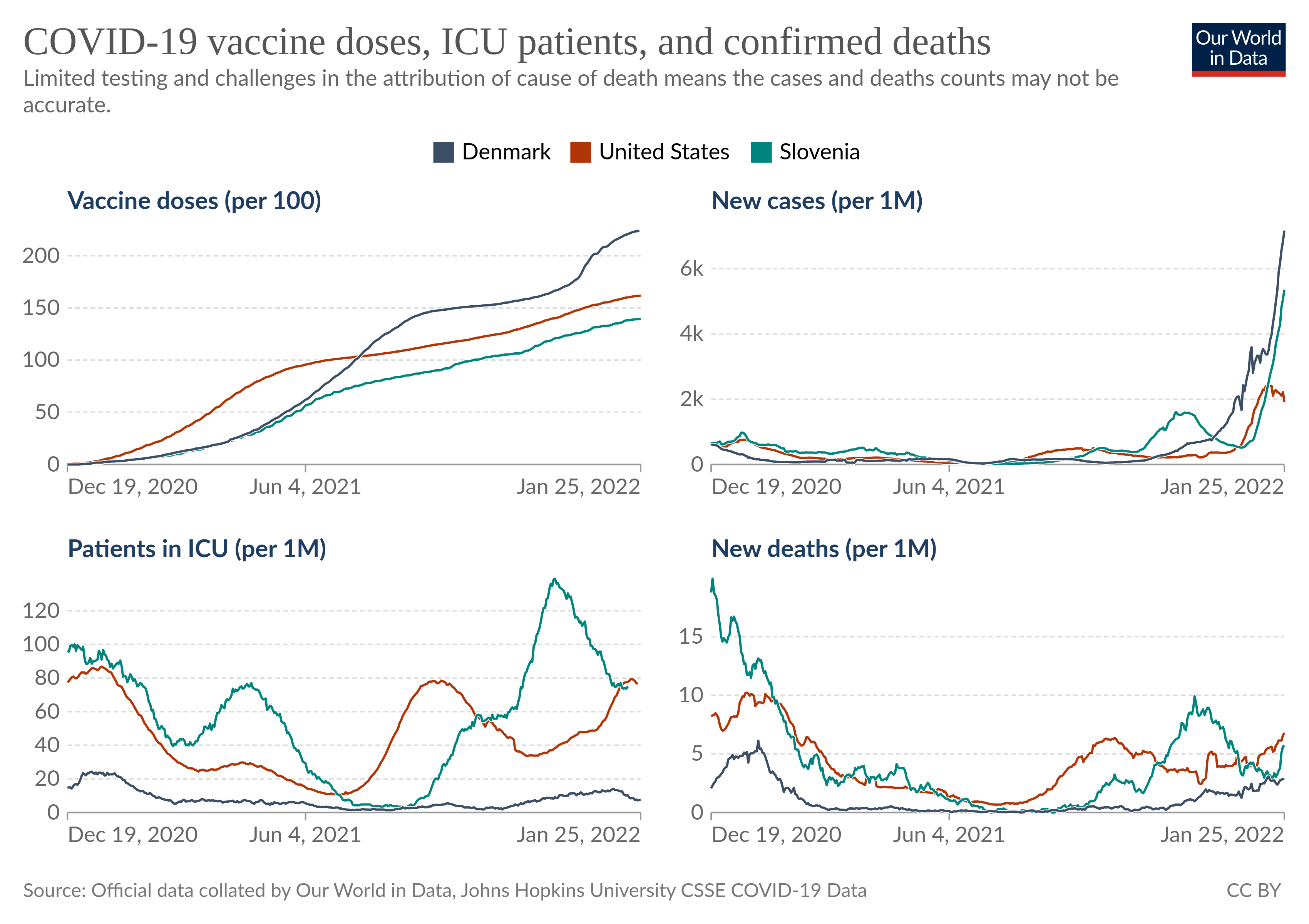
Das Corona-Virus ist hochansteckend. Derzeit geht die Variante Omikron in Form von BA.5 herum. Wie schon bei den Vorvarianten hört man immer wieder, dass ganze Familien erwischt werden. In einem Thread auf Twitter schätzt @fischblog die Wahrscheinlichkeit auf unter 50%, wenn man mit Infizierten in einem Haushalt lebt. Quelle scheint die Studie “Secondary Attack Rates for Omicron and Delta Variants of SARS-CoV-2 in Norwegian Households” zu sein. Diese etwa 50% würde ich nun gern auf 0% oder nahe 0% bringen.
Ziel
Wie ich schon schrieb, geht es mir darum, weitere Ansteckungen innerhalb des Haushalts auszuschließen bzw. das Risiko weitgehend zu minimieren.
Maßnahmen
Neben den untenstehenden Maßnahmen gibt es natürlich einiges in der Vorbereitung. Zuallererst steht für mich die Impfung. Alle sollten geimpft sein. Nach meiner Meinung heißt dass derzeit, dass die letzte Impfung gegen SARS-CoV-2 maximal ein halbes Jahr her ist.
Kurzversion
- Person isolieren
- Maske in der Wohnung tragen
- Wohnung gut lüften
- Viruzides Gurgeln
- Kontaminierte Gegenstände waschen, desifizieren oder wegräumen
Isolationszone
Innerhalb der Wohnung sollte es eine Isolationszone geben. Idealerweise ist das ein Zimmer, in dem sich die infizierte Person aufhält. Dort bleibt diese solange, bis sie wieder negativ getestet ist.
Generell erscheint mir wichtig, dass möglichst wenig Luft aus der Isolationszone in den Rest der Wohnung strömt. Das heißt, der Raum selbst sollte gut durchlüftet werden.
In der Isolationszone verbleiben auch alle Gegenstände, die die infizierte Person berührt (Teller, Besteck, Taschentücher, Nahrung etc.). So soll eine “Kontamination” möglichst vermieden werden. Problematisch sind Sachen, die gekühlt werden müssen sowie das Bad bzw. die Dusche. Hier sollte darauf geachtet werden, dass die Räume regelmäßig mit Seife gereinigt oder desinfiziert werden.
Isolation bedeutet aber auch, dass die Person wenig oder gar keinen Kontakt zu anderen hat. Dies ist auf Dauer belastend. Regelmäßige Videokonferenzen, Telefonate oder andere Fernkontakte sind daher wichtig. Beispielsweise kann die Person über einen Videoanruf am gemeinsamen Essen teilnehmen oder anderweitig mit eingebunden werden. Dies erleichtert die Zeit in Isolation enorm.
Belüftung
Das Virus sollte die Wohnung möglichst schnell wieder verlassen. In den warmen Tagen sollten einfach alle Fenster geöffnet sein. Aus meiner Sicht solltet ihr darauf achten, dass der Luftzug nicht Luft aus der Isolationszone anzieht. Unsere Wohnung ist glücklicherweise so beschaffen, dass ich über einen Luftstrom die Luft direkt aus der Wohnung leiten kann.
Für die kälteren Tage habe ich Luftreiniger beschafft. Eines steht in der Isolationszone und tut dort seine Arbeit. In den Aufenthaltsräumen steht auch mindestens einer. Dieser wälzt die Luft mindestens einmal um, bevor der Raum benutzt wird.
Masken
Ein einfaches und wirksames Mittel sind Masken. Wir tragen innerhalb der Wohnung eine FFP2-Maske. Dies ist für mich der Basisschutz, der immer funktionieren muss. Innerhalb unserer Wohnung gibt es einige Bereiche, die so gut belüftet sind und wo kein “infizierter” Luftstrom hinkommt, dort verzichten wir dann auf die Maske.
Hände waschen / desinfizieren
Es kann immer mal sein, dass man in Kontakt mit Gegenständen kommt, die auch die infizierte Person berührt hat. Insbesondere bei gemeinsam genutzten Räumen, wie Bad, besteht die Gefahr mit Virenrückständen in Kontakt zu kommen. Daher muss insbesondere in solchen Situationen ausführlich Hände gewaschen oder desinfiziert werden. Dabei ist Seife und warmes Wasser sehr wichtig.
Prophylaxe bei Exposition
Nun kann es immer sein, dass man mit Viren in Kontakt kommt. Hierzu gibt es eine Empfehlung der Gesellschaft für Krankenhaushygiene zum viruziden Gurgeln. Das heißt, Gurgeln mit
- Kochsalzlösung (1 Teelöffel auf 100 ml, 3 min)
- grünem Tee
- Listerine Cool Mint
und Anwendung von Algovir Nasenspray.
Dies reduziert die Virenlast und vermindert damit auch den Schweregrad der Erkrankung.
Entsorgung der kontaminierten Gegenstände
Wie oben beschrieben, verbleiben die Gegenstände zunächst in der Isolationszone. Diese werden von Zeit zu Zeit ausgeräumt. Geschirr wird sofort mit Seife abgewaschen. Müll wird ordentlich verpackt und in die Mülltonne gegeben.
Erfolgskontrolle
Ob die Maßnahmen funktionieren oder nicht, lässt sich letztlich schwer sagen. Einerseits weiß ich nicht, was ohne jegliche Vorkehrungen passiert wäre. Sofern man sich noch außerhalb der Wohnung bewegt und sich infiziert, ist andererseits auch oftmals unklar, wo die Infektion passierte.
Insgesamt gehe ich davon aus, dass die Maßnahmen sehr helfen, das Infektionsrisiko in der Wohnung abzusenken.
Update: Nach einem Hinweis auf Twitter habe ich den Link zum PDF für das viruzide Gurgeln aktualisiert. Die DGKH hat die Empfehlungen in diesem Jahr aktualisiert.














 Aber was spricht denn gegen Passwörter als Eingabe? Natürlich die Tatsache, dass man selbst verwendete Passwörter nie irgendwo in unklare Webseiten eingibt. Dennoch kann man CrAIyon ein wenig zum Spielen benutzen.
Aber was spricht denn gegen Passwörter als Eingabe? Natürlich die Tatsache, dass man selbst verwendete Passwörter nie irgendwo in unklare Webseiten eingibt. Dennoch kann man CrAIyon ein wenig zum Spielen benutzen.